
· introductory · 12 min read
What is event sourcing?

Definition: A pattern to store and retrieve events in an append-only log.
Seems simple enough. But what does that really mean?
What is event sourcing?
Event sourcing is an architecture pattern that helps manage the series of complex events that make up your business. As time goes on, this pattern can reveal how much one’s process is comprised of a series of events that define the business. If you’re running an ecommerce site, you’ll have predictable, definable events that you can expect. The user visits a page, they do a search, they choose a product, they add it to the cart, etc.
Event sourcing looks to capture these discrete events as micro-states which can be replayed to recreate the current state of the system.
This realization leads to a number of questions, like:
- If everything is an event, why do we not store each event?
- Shouldn’t those events be immutable, since we can’t change the past?
- How should we write and read all of these events?
- How do we rebuild state once we read back those events? These questions have all been answered by using the event sourcing patterns.
The roots of event sourcing
The concept of Event Sourcing can be traced back to Double-Entry bookkeeping, which was invented in 1494 by Luca Pacioli. Double-entry bookkeeping is a method of recording transactions where for every business event, an entry is recorded in at least two accounts as a debit or credit. These series of discrete events that continually impact the current state of the accounting are in essence what event sourcing is.

This approach provided a systematic and reliable method for recording financial transactions. It offered a clear representation of the financial health of a business and became a cornerstone of modern accounting.
Event sourcing is similar in that it involves capturing discrete events as they occur in a system. Each event represents a state-changing occurrence, and these events are recorded in a chronological order. The historical log of events allows for the reconstruction of the system’s state at any point in time.
In essence, event sourcing draws inspiration from the idea that events, or transactions, are the building blocks of system state, and recording them over time provides a rich historical context. The connection to double-entry bookkeeping emphasizes the importance of tracking changes and events to understand the evolution of a system, just as double-entry bookkeeping allows for a clear understanding of the financial history of a business.
How is event sourcing different than CRUD?
We’ve had relational databases for a over 50 years and they are incredible. They are ridiculously good at retrieving data effectively and relating it to other data with an elegant query language. To this day the majority of applications are built using relational databases and using a CRUD pattern to store and retrieve that data.
For those who aren’t familiar, CRUD is an architecture strategy that focuses on Create, Read, Update, and Delete -> CRUD. What that means is you have an Entity that usually maps to an ORM (Object Relational Mapper) which helps map those fields to the Entity. So, if you have a User object, and you create a new User you’d just map the new username, and email to that object and it would automatically persist that to the database (ID is usually auto generated in this strategy). To read back data it works basically the same. With an ORM it generates the query to read that User and flushes out the object and returns it to you. Voila!
Here’s the rub: At its heart a relational database is a spreadsheet. All of your data is laid out into tables that really lend themselves to current state.
For example, let’s take a look at a User table. As you can see below, we’ve got a User table that shows the id, username, email:
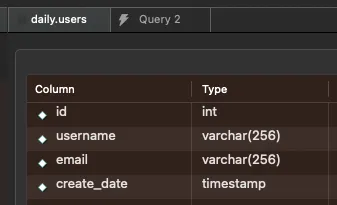
If the user updates their username we have no idea about that change.
- Why did they change it?
- When did they change it?
- What was it before the change?
- How did they change it?
- Do we even know who did it?
As you can see we’ve lost all historical context of that change. A lot of you will have tried to come up with strategies to overcome this. Perhaps you’ve written other tables to track any changes over time. But this gets complicated and you end up polluting your database with tables to attempt to track other tables changes, and then attempting to write application code to wrangle with these deltas.
How is event sourcing different?
Event sourcing tracks each individual change over time through a series of events that can then be replayed. For the example above we’d have events like:
- UserSignedUp
- UserChoseUsername
- UserChangedEmail
These events would look something like this:
UserSignedUp
{
"userId": "95f1fc8c-f379-49d1-a000-f1163f2ffa95"
}But, let’s say the user next chooses a username, then you’d capture that as an event:
UserChoseUsername
{
"userId": "95f1fc8c-f379-49d1-a000-f1163f2ffa95",
"username": "ShakeYourMoneyMaker"
}Which would contain the users new username.
Next the user would add their email address, so you’d create that event:
UserChangedEmail
{
"userId": "95f1fc8c-f379-49d1-a000-f1163f2ffa95",
"email": "[email protected]"
}…which would contain their email address.
These series of events replayed become the current state of the user. And as you can see, we’ve answered all the questions. If we look at the UserChoseUsername event we can understand:
- Why did they change it? → They signed up
- When did they change it? → Timestamp is attached
- What was it before the change? → They didn’t have one
- How did they change it? → They did it from the UI
- Do we even know who did it? → The user did it (we know from the event name, we could have another event for CsrChangedUsername)
The last point I want to make about CRUD is that when you architect a system using a relational database, the services almost inevitably query the database by pulling the data at runtime. This means that when your service is called, it makes a request to the database to run a SQL query and retrieve the data it needs. This strategy ends up adding latency to your system since that query has a cost. Sometimes it’s super fast, but other times you’ll have a query that isn’t optimized, or you just have a lot of data to extract. This is only compounded with the move to microservices, which has allowed engineers to daisy chain microservices, thus exacerbating the latency. If there are multiple microservices with a response time of 3 seconds, and a microservice that needs to call them in succession, those 3-second times quickly turn into 9, 12, 15-second response times. This is catastrophic.
With event sourcing, there is an alternative strategy of streaming those events to the services that need it through the same pub/sub model used for event-driven architectures. This allows the services to be updated in real time since they are notified whenever an event has occurred. This allows those microservices to manage their data as they see fit. This means you can use whatever storage mechanism makes sense for that microservice, be it relational, document, index engine, or even in memory. This can be the panacea for the microservice spaghetti calls, meaning the microservice may not even have to rely on a call to another microservice, since it can subscribe to the required changes that are needed.
For example, if you have an OrderService that would normally inherently rely on a UserService to fetch user details, you’d now be able to subscribe to specific user events or streams that are needed for your OrderService and would never need to call the UserService directly. And those user details your OrderService cares about could be persisted in a more elegant and retrievable manner as you see fit.
Persistence
The first order of business is how to persist events. There are a few requirements that go into persisting events.
- Immutability: Events need to be immutable. That means they cannot change. If you think about your life and the events that have happened to you those events make who you are and are unchanging. Events in your business process are the same and this is the fundamental difference between CRUD and event sourcing. This requires an immutable data store to enforce that rule of immutability.
- Streams: A stream is a collection of events that are all related to each other. If we look at it from the viewpoint of a relational database, this would be our row(ish). If we have look at our previous user example, and we’re tracking the events that are persisted for this user we’d have events like UserSignedUp, UserChoseUsername, UserChangedEmail. These would all go into the stream for this specific user and could be replayed to rebuild the current state of this user (more on this later).
- Data Store: Most engineers are deeply familiar with conventional data stores like relational databases (Oracle, Postgres) or document databases (MongoDB) and would try to use one of those to persist events. While possible this adds a huge amount of complexity and requires you to solve a lot of already solved problems like immutability and streaming capabilities.
Other folks want to use Kafka or some other messaging bus as a way to stream events; however, this limits how and when you’re able to effectively replay events and can get really clumsy really quickly.
The best choice is to use EventStoreDB as a persistence. It solves all the problems related to event sourcing because it was built specifically for this purpose. Event store is a distributed system build around an append-only log which solves for immutability as well as a high throughput storage strategy.
The alternative is to use a relational database, which for event sourcing is not optimal due to its inherent design focused on representing the current state of data rather than capturing historical changes. In a relational database, updating records overwrite existing values, erasing the historical context of changes making them mutable. This limitation makes it challenging to trace the sequence of events, understand historical states, and reconstruct the system’s evolution over time. Additionally, handling the continuous creation of tables or columns to track changes can result in a complex and inefficient database schema, leading to performance issues and increased maintenance overhead. EventStoreDB, designed specifically for event sourcing, offers a more suitable alternative by ensuring immutability and efficient storage of events in an append-only log, enabling the reconstruction of system states accurately.
As for Kafka and other message buses, they are effective for building event-driven architectures, but they aren’t the best choice for event sourcing. Kafka focuses on real-time data streaming and message distribution between disparate systems, providing durability and fault tolerance. However, its design as a distributed commit log lacks the native capabilities needed for efficient event replay and state rebuilding, critical aspects in event sourcing. The inherent complexity of managing offsets and handling replay scenarios in Kafka can lead to cumbersome implementations and reduced performance. EventStoreDB, on the other hand, excels in managing event streams, enforcing immutability, and facilitating efficient event replay, making it a more purpose-built solution for event sourcing scenarios.
Also, Event Store has multiple ways to playback events, making the recreation of state way easier than with other data stores.
What are the benefits of event sourcing?
- Historical Tracking and Auditability: Events represent a chronological log of changes in the system. This historical trail provides a detailed audit log, allowing for easy tracking of changes over time. This can be crucial for compliance, debugging, and understanding the evolution of the system.
- Improved Data Consistency: Since events are append-only and immutable, there is no risk of data being accidentally or maliciously overwritten. This ensures data consistency and integrity, especially in scenarios where the system needs to be rolled back to a specific point in time.
- Decoupling and Scalability: Event sourcing promotes loose coupling between components. Different parts of the system can independently react to events, enabling greater scalability and flexibility. This is particularly advantageous in microservices architectures.
- Flexibility and Evolution: Events represent a flexible and extensible data structure. New events can be added to accommodate changes in business requirements without affecting existing components. This flexibility supports system evolution over time.
- Debugging and Troubleshooting: The detailed event log provides a rich source of information for debugging and troubleshooting. Developers can trace the sequence of events leading to a particular state, making it easier to identify and resolve issues.
- Temporal Queries and Analysis: The historical event log allows for temporal queries, enabling analysis of how the system state has changed over time. This is valuable for business intelligence, trend analysis, and understanding user behavior.
What is the difference between event sourcing and event driven architecture?
The fundamental difference is that event driven architecture is a way to loosely couple disparate systems together to react to particular events, whereas event sourcing is using events to manage all the state in your application. For example, a user completes the sign up flow on your ecommerce site and you want to send a welcome email. Historically, you’d have your system connected to a message bus of some kind (RabbitMQ, SQS) and you’d create a UserSignedUp event with all the details of that event and related data and have your notification service listen as a consumer on that message queue and send the email.
This is an effective way to notify systems of important events that will drive functionality and has been used forever (20+ years) in enterprise application development. However, when you take that concept one step further and come to the conclusion that all events should be persisted and streamed, you now have a new set of architectural issues to contend with. This is where event sourcing comes in. It’s a set of patterns that effectively allow you to replay events to rebuild state. Since it’s a set of patterns there are some key concepts to understand. This summary will dive into the rough understanding of how, why and when you event source.

Matt Macchia
Matt Macchia is a seasoned tech executive and leader of Eventual Tsunami. Starting his career on the original launch team for Hotwire.com with Spencer Rascoff, and more recently leading teams at Event Store, IBM and Audacy. With a passion for delivering features and products driven from our open-source community.